Quicktake: BPE, WordPiece, and SentencePiece
Series - Deep Learning
Contents
This post draws upon information from:
- The documentation of tokenizers by Hugging Face.
- An overview of WordPiece, BPE, and SentencePiece by Masato Hagiwara.
1 WordPiece, BPE, and SentencePiece
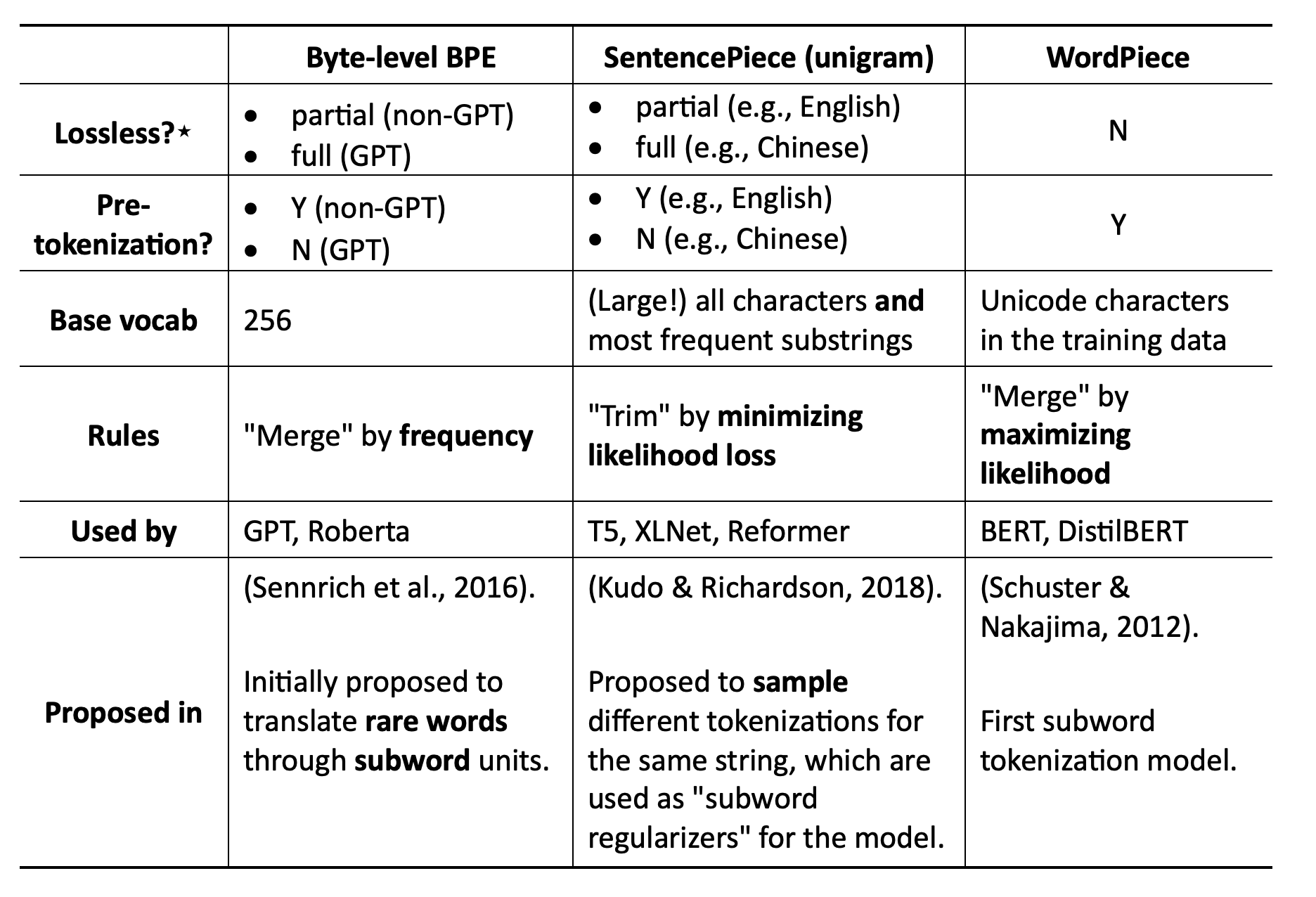
- Mainstream tokenization for neural models can be summarized as: BPE by default; maybe SentencePiece for multilingual. BPE‑dropout may become more widespread due to its simplicity.
- Byte‑level BPE (BBPE) and SentencePiece (unigram) are two popular variants.
- BPE vs. SentencePiece (unigram)
- BPE is greedy and deterministic. It cannot sample different tokenizations for the same string. BPE‑dropout, however, introduces stochasticity.
- In SentencePiece, tokens have probabilities; sampling during tokenization is possible.
- “Lossless” is a matter of degree.
- BPE (GPT) is “fully” lossless. It keeps any length of consecutive spaces.
- SentencePiece (XLNet) is “partially” lossless. It keeps only one space for multiple consecutive spaces.
- WordPiece is lossy. It does not preserve spaces.
2 References
- Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cappelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., & Launay, J. (2023). The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only (arXiv:2306.01116). arXiv. https://doi.org/10.48550/arXiv.2306.01116
- Dowling, M., & Lucey, B. (2023). ChatGPT for (Finance) research: The Bananarama Conjecture. Finance Research Letters, 53, 103662. https://doi.org/10.1016/j.frl.2023.103662
- Xiong, R., Yang, Y., He, D., Zheng, K., Zheng, S., Xing, C., Zhang, H., Lan, Y., Wang, L., & Liu, T. (2020). On layer normalization in the transformer architecture. International Conference on Machine Learning, 10524–10533.
- Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units (arXiv:1508.07909). arXiv. https://doi.org/10.48550/arXiv.1508.07909
- Schuster, M., & Nakajima, K. (2012). Japanese and Korean voice search. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5149–5152. https://doi.org/10.1109/ICASSP.2012.6289079
- Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language‑independent subword tokenizer and detokenizer for Neural Text Processing (arXiv:1808.06226). arXiv. https://doi.org/10.48550/arXiv.1808.06226