Pandas may be the bottleneck of your neural network training
One day I saw the following CPU/GPU usage:
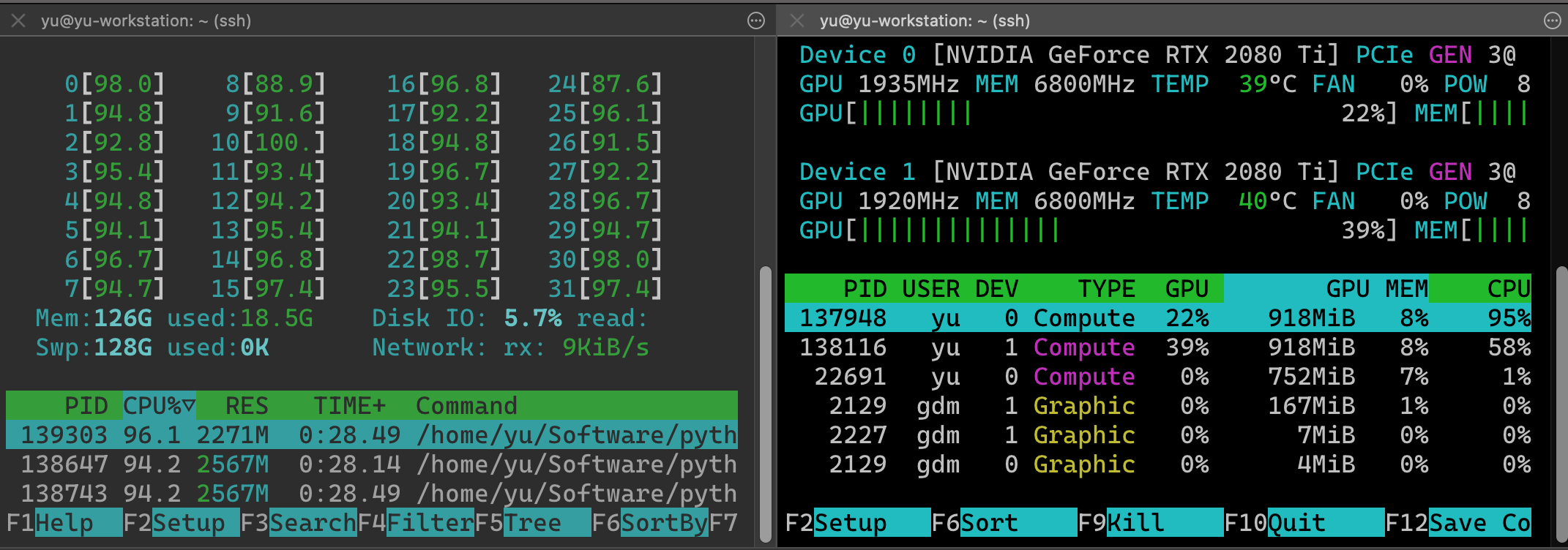
The model is simple, just a two-layer MLP with only structural input features. We can see from the screenshot that the CPU usage is full while GPU is less than half-used. It’s clear that we hit a CPU bottleneck: The CPU is busy feeding data (the dataloader module in pytorch) to GPU while the GPU is always hungry. The question is how to mitigate it. As I said, the model is rather simple, it doesn’t make sense to me that such a simple model will saturate the CPU.
Then I suddenly realized that the culprit may be pandas. In my code, the original data is saved as a pd.DataFrame. Each time the pytorch dataloader will randomly sample one row and extract the inputs (x) and outputs (y). The code is as follows. In pytorch, I created a customized torch.utils.data.Dataset and overrides the __getitem__ function:
def __getitem__(self, idx):
# self.data is a pd.DataFrame
row = self.data[idx]
y = row['y']
x = row['x']
return (y, x)The problem is, indexing a row from a pd.DataFrame is order of magnitudes slower than indexing from a native python dict or np.array. Even though I have a 16 core 32 thread CPU, the task is still too burdensome.
Luckily, we can easily solve the problem by converting our data to a np.array. First, we need to create two arrays in __init__, one for the input features and one for the outputs:
def __init__(self, data):
# Args:
# data: pd.DataFrame. The original data.
self.x = data[['x']].to_numpy()
self.y = data[['y']].to_numpy()Then in __getitem__, we can index the numpy array instead of a pandas DataFrame:
def __getitem__(self, idx):
x = self.x[idx]
y = self.y[idx]
return x, yAs you can see, the CPU usage immediately drops from ~90% to less than 10% and the GPU usage increases from 39% to 62%: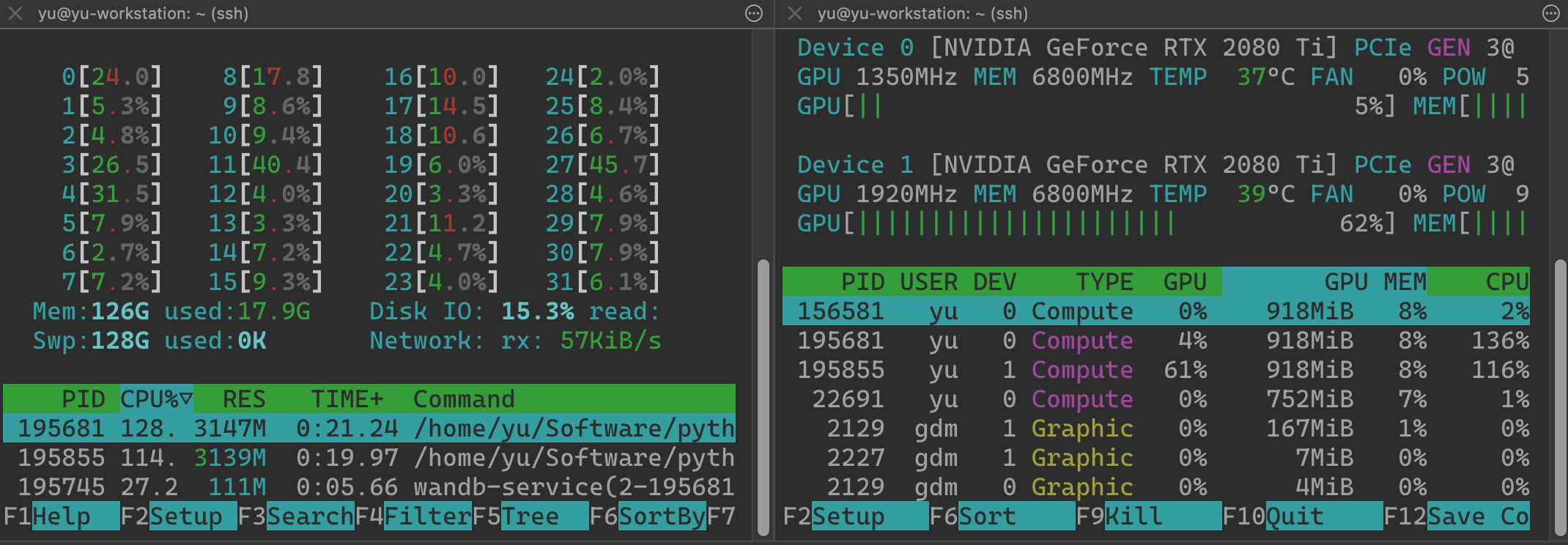
The training time for one epoch also decreases from 44s to 13s.