Nailing down the earnings event time to the millisecond
1 TL;DR
Nailing down the earnings announcement time (ideally to the seconds or milliseconds) is critical to measure market response. However, many databases usually don’t provide a precise event timestamp. For those that do, data quality is questionable, if not confusing.
In this article, I’ll investigate the following four popular databases and tell you which offers the most precise timestamp of earnings events.
The databases and the timestamp variables we’ll look at (all available at WRDS) are:
Compustat (from S&P)
RDQ(report date quarterly) indicates “the earliest time EPS data is public.”RDQis a Date, e.g.,2001-01-01.
Key Development from Capital IQ (hereafter CIQ, also from S&P)
mostImportantDateUTCis a DateTime (e.g.,2001-01-01 12:24:00) precise to the minute (I’ll explain later why it’s not to the second). To use it you need to convert it to Eastern Time.
WRDS SEC Analytic Suite (from SEC and compiled by WRDS)
fdate(filing date),secadate/secatime(EDGAR accepted date/time) are collected from EDGAR. You can find them in thewrds_formstable from WRDS SEC Analytics Suite.
RavenPack (hereafter RP)
timestamp_utcis the news timestamp to the milliseconds. It’s the only variable that offers millisecond-level data.
The filing date (
fdate) and accepted datetime (secadateandsecatime) from the SEC are not the first public time. They have lags.The
rdqfrom Compustat also has lags.The
mostImportantDateUTCfrom Capital IQ is better but still has some issues. If you don’t want to bother with RavenPack, I suggest you use CIQ in the following way:If the time component of
mostImportantDateUTCis zero (e.g., ‘2001-01-01 00:00:00’), then treatmostImportantDateUTCas Eastern Time. In this case, you can’t pin down the precise time of the day but the date should be correct.If it does have a non‑zero time component (e.g., ‘2001-01-01 12:03:00’), converting
mostImportantDateUTCto ET is safe and recommended.
Your best bet is combining RavenPack and CIQ, but it requires a lot of data cleaning.
2 Background: How does the earnings news arrive to you?
We all know the earnings data (e.g., EPS) is from the company. But how soon this data arrives to you depends on the channel. Typically, the earnings data is released and spreads in this order:
A company releases information to all parties at roughly the same time. To the SEC, that will be an EDGAR filing; to the media, it’s a written press release. Note that what the company submits to EDGAR at this time is an 8-K, not a 10-Q. The 8-K only covers critical profit and operations data. The more detailed 10-Q is usually filed days later.
The SEC (EDGAR) takes some time to process the filing before it accepts and publishes it online, creating a lag.
- If the filing is received before 5:30 pm ET, then EDGAR will process it in (usually) less than two minutes and release it afterwards.
- If the filing is received after 5:30 pm, then normally it will have a filing date of the next trading day (see Section 3.2 of this official doc). In this case, the filing date will be one day after the actual event date.
Media outlets, however, are not obliged to validate the information so they may release the news before EDGAR. The lead of media reports could be minutes or even hours.
3 SEC filing date has a lag
As discussed above, the SEC filing date may be later than the media. Here I provide an example.
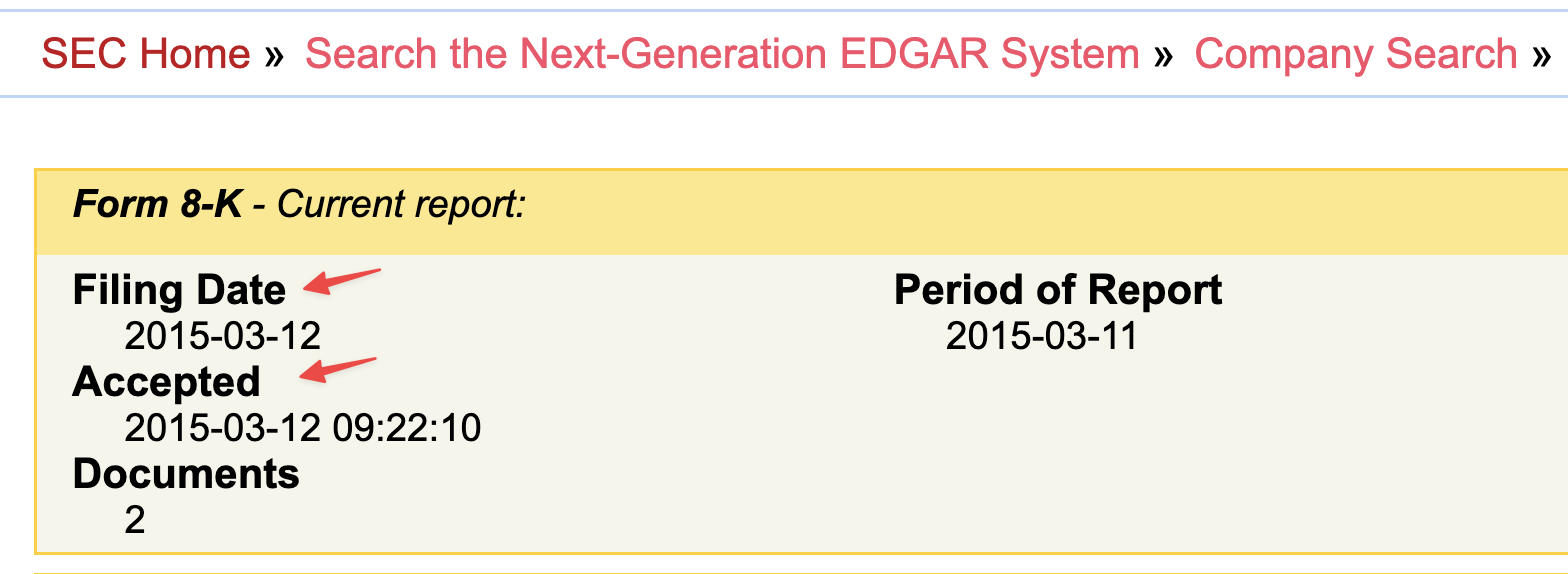
In the screenshot of EDGAR (SEC accession No. 0001171843-15-001360) below, the accepted time is before the EDGAR close time (5:30 pm ET), so the filing date (fdate) and accepted date (secadate) are on the same day.
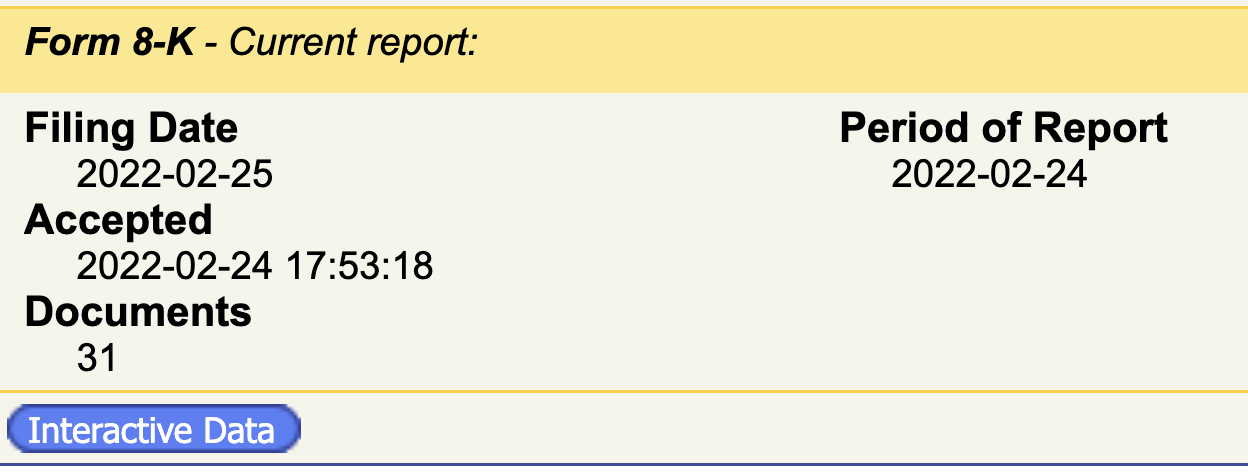
In contrast, in the following screenshot, the filing date is one day after the accepted date since it’s submitted after 5:30 pm ET:
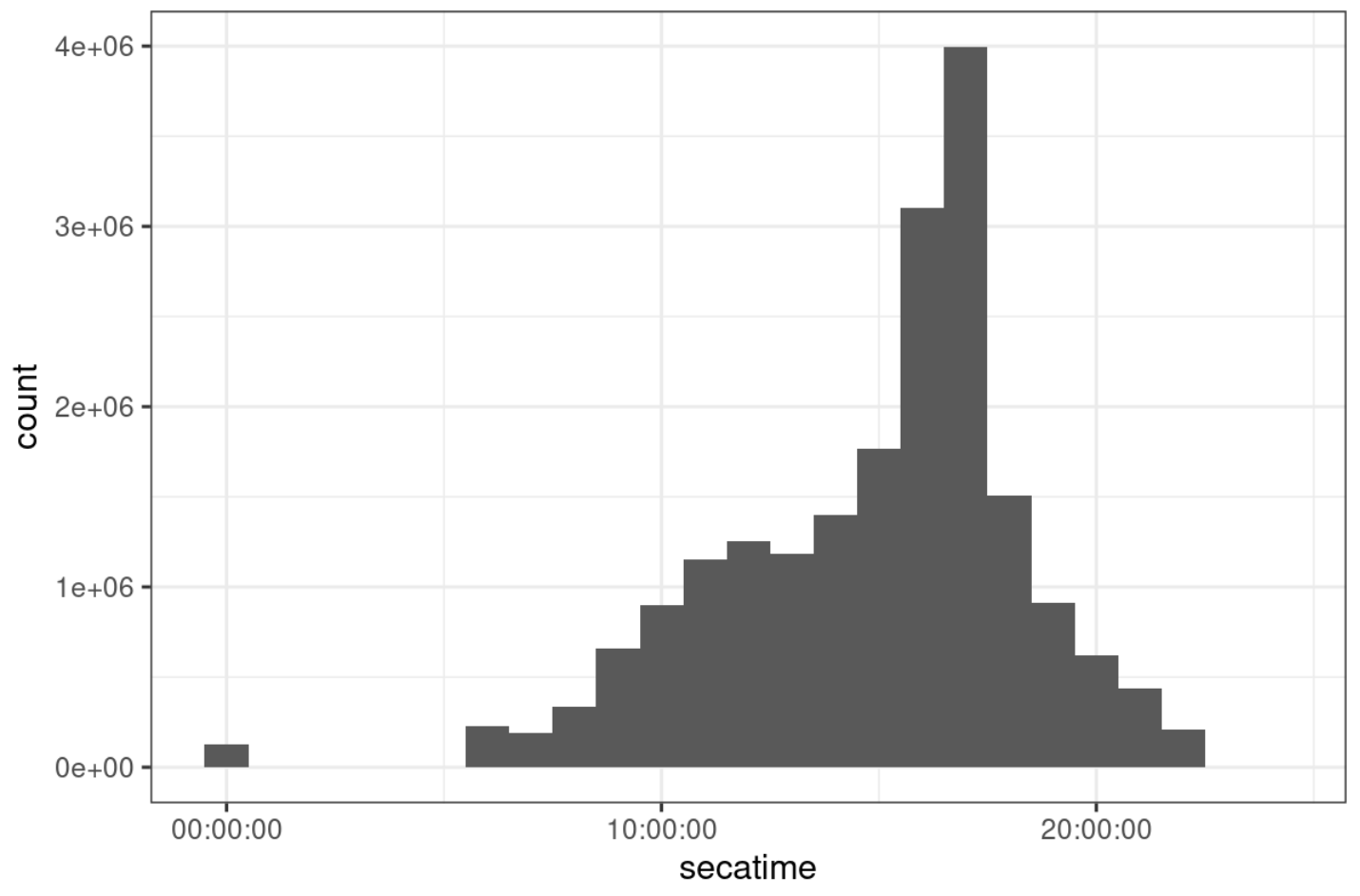
The official manual of EDGAR also says EDGAR only accepts filings between 6 am and 10 pm ET. As a result, the accepted time of any filing should also be within this range. I checked and confirmed that. (There are a few exceptions whose accepted date is around 00:00:00 though.)
To summarize, SEC dates are generally later than media due to the limitations of EDGAR.
You may find some secadate are years after the fdate:
The reason is that some filings are initially filed on paper and later converted to digital format by EDGAR. Refer to my previous post “The ‘Accepted Date’ from WRDS SEC suite doesn’t match EDGAR” for details.
The issue is almost gone for recent filings:
- For
fdate>='2002-05-01'andforms in ['8-K', '10-Q', '10-K'], thefdateof 98.1% of filings is on the same day or one day behind thesecadate.
4 RDQ is good, but it has no time component
RDQ, the Report Date Quarterly, is described as “the date on which quarterly earnings per share are first publicly reported.”
RDQ is accurate; I found 98% of RDQs agree with other data sources. However, the missing time component makes it impossible to accurately time the market response: If the earnings news is released before market close (4 pm ET), then day 0 is the release date; if news is released after 4 pm ET, then day 0 should be the next trading day. That would make a big difference since a significant portion of market response is on day 0.
Sadly, RDQ doesn’t tell us if the earnings news is released before or after market close.
5 mostImportantDateUTC in CIQ is good, but not perfect
mostImportantDateUTC from CIQ seems to track events more closely. From the same S&P client support I learned that:
So theoretically CIQ can record events before they’re officially released by EDGAR. Sounds good, right?
Unfortunately, mostImportantDateUTC has three drawbacks:
The time component of some events is missing
In 25.6% of cases, the datetime will be something like ‘2008-09-01 00:00:00’, where ‘00:00:00’ indicates CIQ only records the date.
It’s floored to the minute
I checked the whole CIQ database and found the second component is always zero. That means if the true event time is “17:30:43”, CIQ will floor it to “17:30:00”.
It’s not necessarily the earliest timestamp
After comparing to RavenPack, I found
mostImportantDateUTCis not always the earliest timestamp. There are many cases where the earliest news article in RP is earlier than CIQ.
As a summary, if you don’t want to dig into the RavenPack data, I suggest you use CIQ in the following way:
If the time component of
mostImportantDateUTCis zero (e.g., ‘2001-01-01 00:00:00’), then treatmostImportantDateUTCas if it’s in Eastern Time (i.e., ‘2001-01-01 UTC’ becomes ‘2001-01-01 ET’).If it does have a non‑zero time component (e.g., ‘2001-01-01 12:03:00’), converting
mostImportantDateUTCto ET is safe and recommended (i.e., ‘2001-01-01 12:03:00 UTC’ becomes ‘2001-01-01 07:03:00 EST’).
6 Combine RavenPack and Capital IQ
All news articles in RavenPack are timed to the milliseconds. This makes RP a perfect source for the timing of earnings events. However, since RP focuses on news articles, it’s possible that some events may not be covered by any news media. In addition, RP is big (one year is over 200 GB), and its taxonomy on earnings events is very complex (there are >20 event types related to earnings). This makes matching RP to other databases very difficult.
So your best shot is to join the merits of both: supplement CIQ with RavenPack. The general idea is:
On average, 54% of CIQ timestamps can be improved by RavenPack.
6.1 The logic of code
Combining RP with CIQ is not easy. I first present the logic of the code (so you can implement with other languages) and in the next section, I provide an R example.
Step 1: Split CIQ
- You start with a table called
ciq. This could be the raw Key Development table in CIQ or any cleaned table. The only requirement is that each line ofciqrepresents one earnings event. The most important column inciqwould bemostImportantDateUTC—the event timestamp provided by CIQ. - Split table
ciqinto two tables according to whethermostImportantDateUTChas a time component: tableciqdifmostImportantDateUTConly has the date component, and tableciqdtif it has both a date and a time component.
Step 2: Process ciqd
Since there’s no time component, we’ll create a default one. It equals the last second of the
RDQday. That is, ifRDQis2001-01-01, the default timestamp would be2001-01-01 23:59:59.Join
ciqdto the RavenPack table: for every earnings event inciqd, query the previous 2 days in RP. If you find a match, update the event time from the default (23:59:59) to the RP timestamp.
Step 3: Process ciqdt
For each event in
ciqdt, query the previous 12 hours in RP. If there’s a match, label the retrieved RP timestamp as"match_prev".Similarly, for the same event, query the next 60s in RP. Label the retrieved RP timestamp as
"match_next". This step addresses the flooring to minute issue.Now each event in
ciqdthas three statuses depending on what type of RP timestamp it successfully retrieved:- Failed to match any RP timestamp. We then use the CIQ timestamp (
mostImportantDateUTC). - Matches at least one
"match_prev"timestamp (including the case where it matches both"match_prev"and"match_next"). This means we successfully find an earlier timestamp in RP. We then use the"match_prev"timestamp. - Matches only a
"match_next"timestamp. This means the CIQ timestamp is earlier than any other media by no more than 60 seconds. It’s an indicator of the flooring issue. In this case, we use the"match_next"timestamp.
- Failed to match any RP timestamp. We then use the CIQ timestamp (
Step 4: Combine ciqd and ciqdt
6.2 R Code
The R code is not fully reproducible since I omitted hundreds of lines of data cleaning code. But the main logic is untouched.
I relied heavily on the data.table package: you’ll write many more lines of code if you use its competitors like dplyr or pandas.
library(stringr)
library(data.table)
library(lubridate)
library(hms)
# ---- Define the tables and columns we'll use ----
# - ciq: This could be the raw "Key Development" table in CIQ or any cleaned table.
# The only requirement is that each line of `ciq` represents *one earnings event*.
# The most important column in `ciq` would be `ciq_ann_dttm_utc` -- the event timestamp
# provided by CIQ (it's just a rename of `mostImportantDateUTC).
#
# - rp: The RavenPack table. Each line is an "event" (see the RP manuals for how RP defines an
# entity and an event)
#
# Example of ciq:
# gvkey rp_entity_id rdq ciq_ann_dttm_utc
# 1: 014535 BDE867 2021-05-07 2021-05-07 11:30:00
#
# Example of rp:
# rp_entity_id rp_story_id rp_dttm_utc source_name
# 1: D502AB E75346353C34D9DA358AB6F344108EF9 2007-12-21 13:07:59 Canadian News Wire
# ---- Step 1: split ciq into two tables ----
# ciqd: only has date information (74%)
# ciqdt: has both date and time information (26%)
ciqd = ciq[as_hms(ciq_ann_dttm_utc)==0]
ciqdt = ciq[as_hms(ciq_ann_dttm_utc)!=0]
dobs(ciqdt, ciqd)
# ---- Step 2: Process ciqd ----
# assign default timestamp: 23:59:59 on RDQ day
ciqd[, ':='(joindttm=as_datetime(rdq, 'America/New_York')+as.numeric(as_hms('23:59:59')))]
ciqd_rp_1 = rp[, ':='(joindttm=rp_dttm_utc)
# query previous 2 days
][ciqd,
on=.(rp_entity_id, joindttm),
roll=2*24*3600, nomatch=NULL
# headlines should not include "to report" -- these news are
# not the actual earnings results, but just a notification that
# the company will release earnings soon.
][!str_detect(headline, regex('to report', ignore_case=T))
# keep the earliest RP timestamp
][order(gvkey, rdq, rp_dttm_utc)
][, .SD[1], keyby=.(gvkey, rdq)
][, .(gvkey, rdq, rp_dttm_utc, rp_story_id, headline)]
# merge ciqd_rp back to ciq
ciqd_rp_2 = ciqd_rp_1[ciqd, on=.(gvkey, rdq), nomatch=NA
][, ':='(joindttm=NULL)]
# ---- step 3: Match ciqdt ----
# query previous 3 hours
ciqdt_rp_locf = rp[, ':='(joindttm=rp_dttm_utc)
# search for the previous 3 hours in RP
][ciqdt[, ':='(joindttm=ciq_ann_dttm_utc)],
on=.(rp_entity_id, joindttm),
roll=3*3600, nomatch=NULL
# keep the earliest RP timestamp
][order(gvkey, rdq, rp_dttm_utc)
][, .SD[1], keyby=.(gvkey, rdq)
][, .(gvkey, rdq, rp_dttm_utc, rp_story_id, headline, jointype='match_prev')]
# query next 60 seconds
ciqdt_rp_nocb = rp[, ':='(joindttm=rp_dttm_utc)
# search for the next 60 seconds (to deal with the flooring issue)
][ciqdt[, ':='(joindttm=ciq_ann_dttm_utc)],
on=.(rp_entity_id, joindttm),
roll=-60, nomatch=NULL
# keep the earliest RP timestamp
][order(gvkey, rdq, rp_dttm_utc)
][, .SD[1], keyby=.(gvkey, rdq)
][, .(gvkey, rdq, rp_dttm_utc, rp_story_id, headline, jointype='match_next')]
# combine results
ciqdt_rp_1 = rbindlist(list(ciqdt, ciqdt_rp_locf, ciq_rpdt_nocb), use.names=T, fill=T)
ciqdt_rp_1 = ciqdt_rp_1[!str_detect(headline, regex('to report', ignore_case=T)),
.(gvkey, rdq, rp_dttm_utc, rp_story_id, headline, jointype)]
# determine which RP timestamp to use
ciqdt_rp_2 = ciqdt_rp_1[order(gvkey, rdq, jointype)
][, {
# if no match, keep original CIQ timestamp
if (all(is.na(jointype))) {
out = .SD[1]
# if at least matches to one earlier news article in RP,
# use the RP timestamp
} else if ('match_prev' %in% jointype) {
out = .SD[jointype=='match_prev'][1]
# if only matches to a RP timestamp no later than 60s,
# use the RP timestamp
} else if ('match_next' %in% jointype) {
out = .SD[jointype=='match_next'][1]
}
out
},
keyby=.(gvkey, rdq)
][, .(gvkey, rdq, rp_dttm_utc, rp_story_id, headline)]
# merge ciqdt_rp back to ciq
ciqdt_rp_3 = ciqdt_rp_2[ciqdt, on=.(gvkey, rdq), nomatch=NA
][, ':='(joindttm=NULL)]
# if rp_dttm_utc and ciq_ann_dttm_utc are the same, then
# assign rp_dttm_utc a NA
#
# in the final dataset:
# - 45% failed to match any RP or CIQ and RP have the same timestamp
# - 27% RP is later than CIQ (the flooring issue)
# - 28% RP is earlier than CIQ
ciqdt_rp_3 = ciqdt_rp_3[rp_dttm_utc==ciq_ann_dttm_utc, ':='(rp_dttm_utc=NA)]The results:
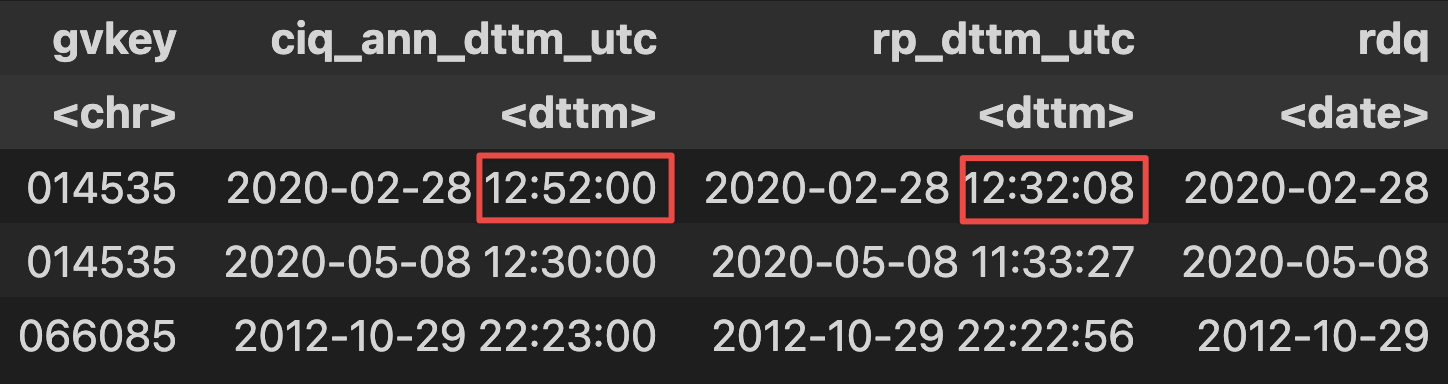
As you can see, in the first line, CIQ timestamp is 12:52:00 while the earliest RP timestamp is 12:32:08.