One Figure to Summarize PyTorch Memory Management
(The text below is generated by ChatGPT‑4 and verified by me. The figure above, however, is created by me.)
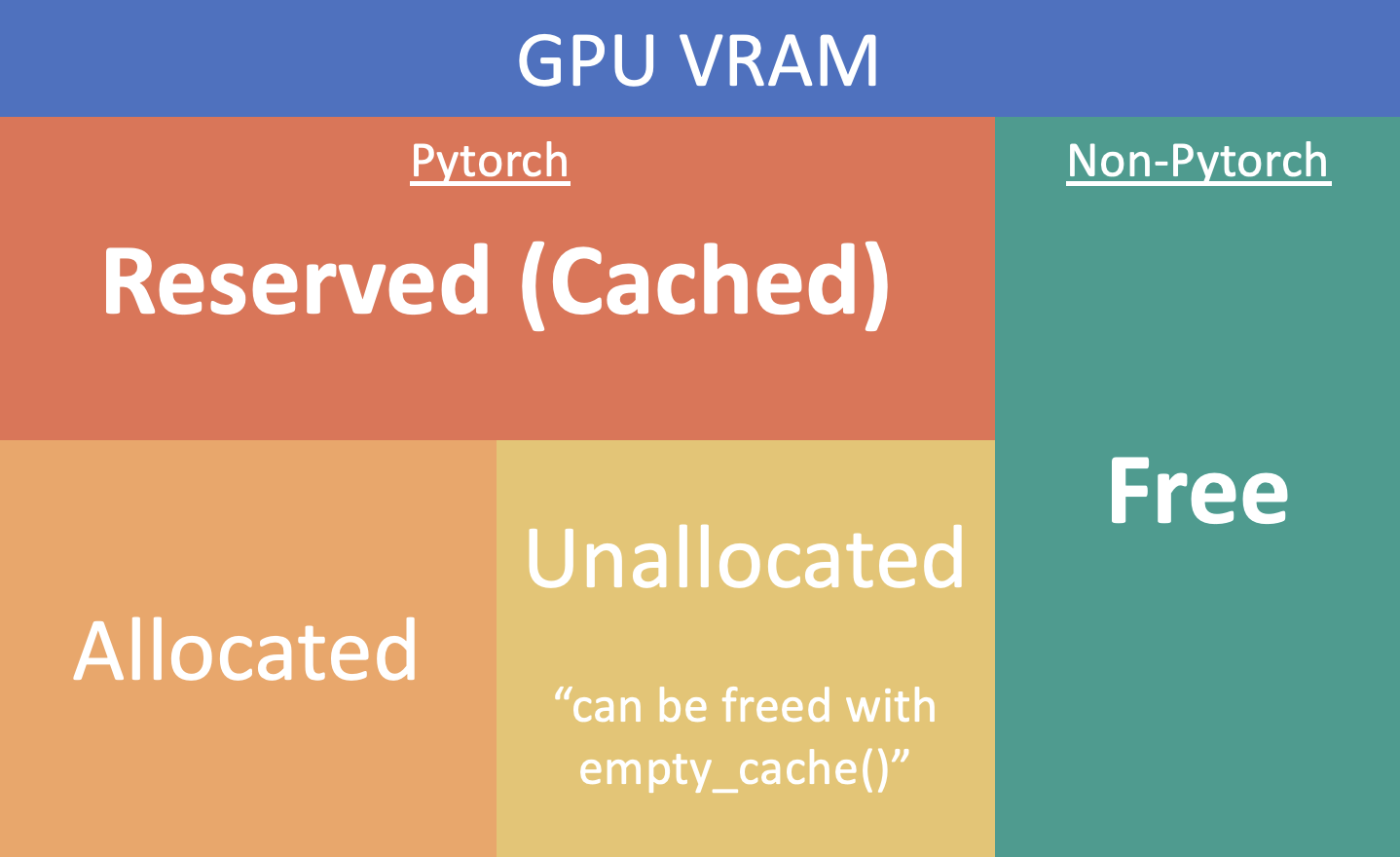
In PyTorch GPU memory management, the terms “allocated,” “unallocated,” “free,” “reserved,” etc., refer to different states of GPU memory usage. These terms help users understand how PyTorch handles GPU memory under the hood, which is especially important for optimizing applications and troubleshooting out‑of‑memory errors.
Here’s what each term generally means:
Allocated memory: The amount of memory currently used by active tensors in PyTorch. When you create a tensor or a model parameter, PyTorch allocates GPU memory to store its values. This memory is considered allocated until the tensor is deleted or goes out of scope.
Cached (or reserved) memory: PyTorch uses a caching memory allocator to manage GPU memory more efficiently. When memory is allocated for the first time, the allocator often reserves a larger block of memory than requested. This reserved memory is ready for future allocations without asking the GPU driver for more memory, which is relatively slow.
Unallocated (but cached/reserved) memory: Memory reserved by PyTorch’s allocator but not currently allocated to any tensor. It’s a pool immediately available for new tensors without an expensive allocation with the GPU driver.
Free memory: Often refers to memory truly free—not reserved by PyTorch and returned to the GPU for other applications. GPU monitoring tools may report “free” memory differently from PyTorch’s “unallocated” because PyTorch can hold reserved memory that appears as used externally.
Max memory allocated: The peak amount of GPU memory allocated by tensors at any point during a program’s lifetime.
Max memory reserved: The peak amount of memory reserved by the caching allocator during a program’s lifetime.